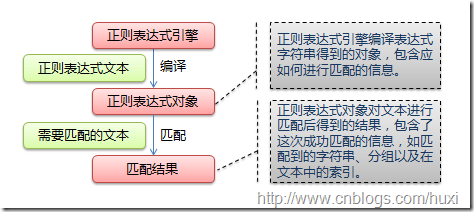
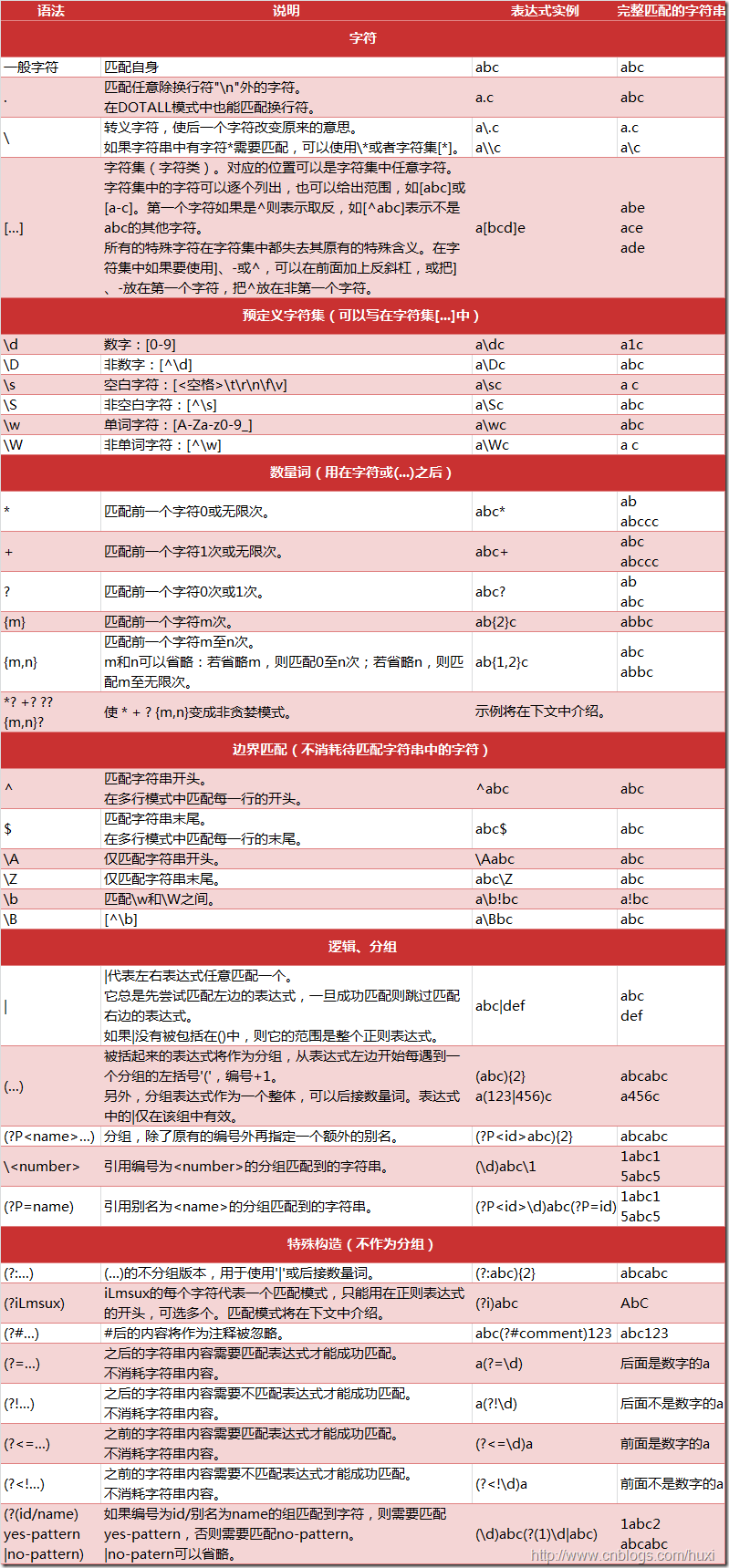
''' |
- compile 函数
- match 函数
- search 函数
- findall 函数
- finditer 函数
- split 函数
- sub 函数
- subn 函数
使用方式
- 生成模式
import re
pattern = re.compile(r'\d+')
dir(pattern)
...,
'findall',
'finditer',
'flags',
'fullmatch',
'groupindex',
'groups',
'match',
'pattern',
'scanner',
'search',
'split',
'sub',
'subn'
match方法
match 方法用于查找字符串的头部(也可以指定起始位置),它只一次匹配,只要匹配成功,不再继续查找match(string[, pos[, endpos]])
#coding:utf8 |
search 方法
search 方法用于查找字符串的任何位置,它也是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果,它的一般使用形式如下:search(string[, pos[, endpos]])
import re |
例子
# -*- coding: utf-8 -*- |
findall方法
上面的 match 和 search 方法都是一次匹配,只要找到了一个匹配的结果就返回。然而,在大多数时候,我们需要搜索整个字符串,获得所有匹配的结果。
findall 方法的使用形式如下:
findall(string[, pos[, endpos]]) |
例子:
import re |
finditer 方法
finditer 方法的行为跟 findall 的行为类似,也是搜索整个字符串,获得所有匹配的结果。但它返回一个顺序访问每一个匹配结果(Match 对象)的迭代器。# -*- coding: utf-8 -*-
import re
pattern = re.compile(r'\d+')
result_iter1 = pattern.finditer('hello 123456 789')
result_iter2 = pattern.finditer('one1two2three3four4', 0, 10)
print type(result_iter1)
print type(result_iter2)
print 'result1...'
for m1 in result_iter1: # m1 是 Match 对象
print 'matching string: {}, position: {}'.format(m1.group(), m1.span())
print 'result2...'
for m2 in result_iter2:
print 'matching string: {}, position: {}'.format(m2.group(), m2.span())
# 返回结果
type 'callable-iterator'>
<type 'callable-iterator'>
result1...
matching string: 123456, position: (6, 12)
matching string: 789, position: (13, 16)
result2...
matching string: 1, position: (3, 4)
matching string: 2, position: (7, 8)
split 方法
split 方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下:split(string[, maxsplit])
import re |
sub方法
sub 方法用于替换。它的使用形式如下:sub(repl, string[, count])
其中,repl 可以是字符串也可以是一个函数:
- 如果 repl 是字符串,则会使用 repl 去替换字符串每一个匹配的子串,并返回替换后的字符串,另外,repl 还可以使用
\id的形式来引用分组,但不能使用编号 0; - 如果 repl 是函数,这个方法应当只接受一个参数(Match 对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
import re |
subn 方法
subn 方法跟 sub 方法的行为类似,也用于替换。它的使用形式如下:
subn(repl, string[, count]) |
它返回一个元组:
(sub(repl, string[, count]), 替换次数) |
看看例子:
import re |
执行结果:
('hello world, hello world', 2) |
其他函数
事实上,使用 compile 函数生成的 Pattern 对象的一系列方法跟 re 模块的多数函数是对应的,但在使用上有细微差别。
match 函数
match 函数的使用形式如下:
re.match(pattern, string[, flags]): |
其中,pattern 是正则表达式的字符串形式,比如 \d+, [a-z]+。
而 Pattern 对象的 match 方法使用形式是:
match(string[, pos[, endpos]]) |
可以看到,match 函数不能指定字符串的区间,它只能搜索头部,看看例子:
import re |
执行结果:
m1 is: None |
search 函数
search 函数的使用形式如下:
re.search(pattern, string[, flags]) |
search 函数不能指定字符串的搜索区间,用法跟 Pattern 对象的 search 方法类似。
findall 函数
findall 函数的使用形式如下:
re.findall(pattern, string[, flags]) |
findall 函数不能指定字符串的搜索区间,用法跟 Pattern 对象的 findall 方法类似。
看看例子:
import re |
finditer 函数
finditer 函数的使用方法跟 Pattern 的 finditer 方法类似,形式如下:
re.finditer(pattern, string[, flags]) |
split 函数
split 函数的使用形式如下:
re.split(pattern, string[, maxsplit]) |
sub 函数
sub 函数的使用形式如下:
re.sub(pattern, repl, string[, count]) |
subn 函数
subn 函数的使用形式如下:
re.subn(pattern, repl, string[, count]) |
到底用哪种方式
从上文可以看到,使用 re 模块有两种方式:
- 使用 re.compile 函数生成一个 Pattern 对象,然后使用 Pattern 对象的一系列方法对文本进行匹配查找;
- 直接使用 re.match, re.search 和 re.findall 等函数直接对文本匹配查找;
下面,我们用一个例子展示这两种方法。
先看第 1 种用法:
import re |
再看第 2 种用法:
import re |
如果一个正则表达式需要用到多次(比如上面的 \d+),在多种场合经常需要被用到,出于效率的考虑,我们应该预先编译该正则表达式,生成一个 Pattern 对象,再使用该对象的一系列方法对需要匹配的文件进行匹配;而如果直接使用 re.match, re.search 等函数,每次传入一个正则表达式,它都会被编译一次,效率就会大打折扣。
因此,我们推荐使用第 1 种用法。
匹配中文
在某些情况下,我们想匹配文本中的汉字,有一点需要注意的是,中文的 unicode 编码范围 主要在 [\u4e00-\u9fa5],这里说主要是因为这个范围并不完整,比如没有包括全角(中文)标点,不过,在大部分情况下,应该是够用的。
假设现在想把字符串 title = u'你好,hello,世界' 中的中文提取出来,可以这么做:
# -*- coding: utf-8 -*- |
注意到,我们在正则表达式前面加上了两个前缀 ur,其中 r 表示使用原始字符串,u 表示是 unicode 字符串。
执行结果:
[u'\u4f60\u597d', u'\u4e16\u754c'] |
贪婪匹配
在 Python 中,正则匹配默认是贪婪匹配(在少数语言中可能是非贪婪),也就是匹配尽可能多的字符。
比如,我们想找出字符串中的所有 div 块:
import re |
执行结果:
['<div>test1</div>bb<div>test2</div>'] |
由于正则匹配是贪婪匹配,也就是尽可能多的匹配,因此,在成功匹配到第一个 时,它还会向右尝试匹配,查看是否还有更长的可以成功匹配的子串。
如果我们想非贪婪匹配,可以加一个 ?,如下:
import re |
结果:
['<div>test1</div>', '<div>test2</div>'] |
小结
- re 模块的一般使用步骤如下:
- 使用 compile 函数将正则表达式的字符串形式编译为一个 Pattern 对象;
- 通过 Pattern 对象提供的一系列方法对文本进行匹配查找,获得匹配结果(一个 Match 对象);
- 最后使用 Match 对象提供的属性和方法获得信息,根据需要进行其他的操作;
- Python 的正则匹配默认是贪婪匹配。
